For various reasons the cluster is heterogeneous, currently ranging from a single Pentium-II 333 MHz to dual Pentium-III 450 MHz CPU machines. Although this will be sufficient for our ``embarrassingly parallelizable problem'' it may present some challenges for as yet unplanned future use. In addition the cluster was used to construct a MIRIAD benchmark, and compared to equivalent Ultra-Sparc based workstations.
Currently the cluster consists of 8 machines, 14 CPUs, 50GB of disk-space, and a total peak speed of 5.83 GHz, or about 1.5 Gflops. The total cost of this cluster has been about $12,000, including all cabling, networking equipment, rack, and a CD-R backup system.
The URL for this project is http://dustem.astro.umd.edu.
Commodity PC hardware components with the virtually freely available Linux operating system now provide a viable alternative compute engine (cf. Beowulf clusters) to the traditional supercomputer and desktop arrangements which most astronomy departments were using up until recently.
Approximately ![]() PDR and Dust Continuum models
are needed (Pound et al. 2000),
each of them requiring about
PDR and Dust Continuum models
are needed (Pound et al. 2000),
each of them requiring about ![]() Gflop's. A typical 10 node
Pentium-II cluster can currently reach about 1 Gflops, and would
provide us with a compute engine that could produce these models
in a few months time.
Each model generates a small amount (about 15kB) of data,
which is copied back to the server, a Solaris machine on which
the web server is running providing
Java clients with a visual interface to the data (Pound et al. 2000).
Gflop's. A typical 10 node
Pentium-II cluster can currently reach about 1 Gflops, and would
provide us with a compute engine that could produce these models
in a few months time.
Each model generates a small amount (about 15kB) of data,
which is copied back to the server, a Solaris machine on which
the web server is running providing
Java clients with a visual interface to the data (Pound et al. 2000).
For a variety of reasons (ramp up, using Moore's law to our advantage, funding cycles in a multi-year project) we decided to build up the cluster over several months. This of course means that one winds up with a non-homogeneous cluster, which may be a handicap for codes that require more symmetric CPUs. In addition, maintenance can be complicated because of different components (video cards, ethernet cards, etc.). Our first two machines (a single CPU Pii-400 and Pii-333) arrived in Spring 1998, and later that year three dual Pii-400s arrived. In Spring 1999 we acquired three more dual Piii-450s, and then finally assembled the 8 boxes/14 node cluster in a rack.
The machines have been networked together with fast (100 Mbit) ethernet and a simple hub, since we did not need more sophisticated I/O other than transferring the final results to a central database. We also keep the cluster on a private network, not only for security reasons, but also to limit public IP usage. In a more serious Beowulf-type cluster, switches with Gigabit networking would be employed to provided faster interprocess communication.
There are a variety of ways to software ``glue'' individual workstations together (all methods are not limited to Linux PCs). These will take care of issues like load-balancing, shared memory across machines etc.
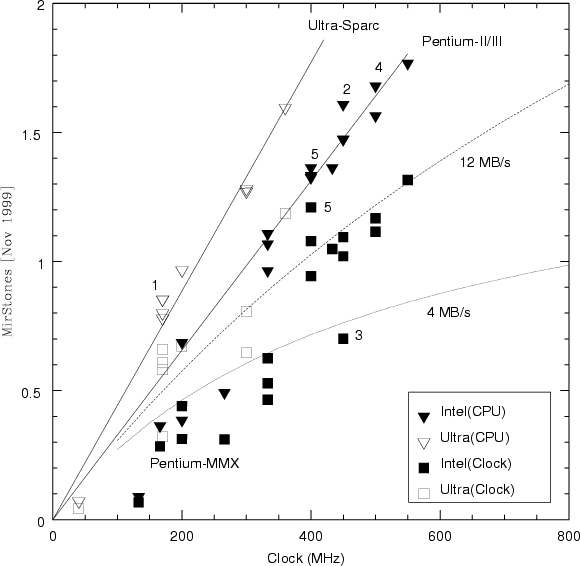
The MIRIAD package (Sault et al. 1995) did not have a standard benchmark (cf. DDT in AIPS) or baseline test. A new benchmark was thus devised (MirStones) to compare different compilers, different Linux distributions, various types of hardware and other operating systems under similar hardware configurations (Teuben 2000) Version 1 of this benchmark tests basic radio interferometric data computing and manipulation (mapping and deconvolution) and produces a modest 350MB of data. A typical benchmark takes 3-8 minutes on a modern workstation, and a MirStone is normalized to unity when the benchmark takes 5 minutes.
Here are the basic ingredients to the benchmark, in MIRIAD terminology:
The following table and figure summarizes and compares a few other popular benchmarks with MirStones:

 |
Pound, M.W. et al. 2000, this volume, 628
DDT, (Dirty Dozen Test), Aips memo 85
Sault R. J., Teuben, P. J., & Wright, M. C. H. 1995, in ASP Conf. Ser., Vol. 77, Astronomical Data Analysis Software and Systems IV, ed. R. A. Shaw, H. E. Payne, & J. J. E. Hayes (San Francisco: ASP), 433
Teuben, P. J. 2000, BIMA memo (in preparation)
Rudolph, A. & Teuben, P. J. 1991, BIMA memo 11.