O. M. Smirnov and A. P. Ipatov
Institute of Astronomy of the Russian Academy of Sciences / Isaac Newton
Institute, Moscow Branch, 48 Pyatnitskaya Str., Moscow 109017 Russia
Photometric observations of globular clusters usually involve enormous amounts of data. A typical data set can consist of several dozen CCD frames produced with two or more different filters and at different exposures, with anything from a few hundred to a few thousand stars present in each frame. Powerful software tools are required if the reductions are to be accomplished at the cost of CPU hours rather than man-hours. The process of data reduction involves two phases:
The first phase can be performed using one of several PSF-fitting stellar photometry packages currently available to the community (PSF fitting is required since the frames are usually too crowded for simple aperture photometry). Of these perhaps, DAOPHOT II (Stetson 1991) is by far the most comprehensive, allowing near-automatic reductions of large batches of data. We are unaware of any packages that provide a complete reduction path for the second phase, which is why we developed DASHA. DASHA can automate the whole process of globular cluster photometry, from instrumental magnitude lists produced by DAOPHOT II, to final color-magnitude diagrams. For example, having reduced 45 CCD frames (3 filters/15 frames each) with DAOPHOT II, you can cross-identify all the stars, calibrate them, produce a table of mean magnitudes in each filter, and obtain color-magnitude diagrams, all within one or two hours.
Several design goals were involved in the development of DASHA:
DASHA is implemented in the PCIPS environment (Smirnov & Piskunov 1994), and takes full advantage of its graphical user interface (GUI). In addition, DASHA constantly displays various plots that allow a user to keep track of exactly what's happening to the data.
DAOPHOT II was selected as a base for DASHA, for two reasons: First, a full version of DAOPHOT II, PCDAOPHOT II, has been implemented under PCIPS. Therefore, both phases of the reduction process can be performed in one environment; and second, DAOPHOT II handles crowded fields very well. Globular cluster observations are usually very crowded.
Functionally, DASHA consists of several modules. Using them in different combinations allows the user to accommodate variations in the reduction process.
DASHA is oriented towards star lists produced by DAOPHOT II as source data. Each star list is an ASCII table with one line per star. The final output lists contain columns for coordinates, instrumental magnitude, magnitude error, goodness-of-fit statistics, etc. The same format (with some extensions) is used throughout DASHA for intermediate and final results.
DASHA contains several modules:
A feature of DASHA (or more specifically, the XID and XFilt modules) that is crucial to its productivity is the ability to automatically cross-identify objects between frames. Frames are not always aligned in position, so to perform a cross-identification, DASHA must first find the positional offset between them. DASHA finds the offset by automatically selecting a set of positional standards, i.e., objects that seem to be present in both frames. Once it has the standards, it can compute the mean offset; and once it has the mean offset, the rest is trivial.
Clearly, the actual selection of standards is not so trivial. DASHA approaches the problem much like a human would: it compares the two frames to see which patterns of stars seem similar. More specifically, it starts out by selecting at random a bunch of two-star patterns on one frame, and tries to find similar patterns on the second frame (each pair of corresponding patterns is called a cluster.) Next, it attempts to grow each cluster by adding a star at random to the pattern on the first frame. If the second frame also has a star at the expected position, both stars are added to the respective patterns. When DASHA repeats this step over and over, clusters with correctly cross-identified patterns tend to grow, while misidentified ones don't. DASHA drops those clusters that do not grow for a specific time
Once the clusters contain enough stars, DASHA performs a few more idle loops to let any remaining misidentifications perish, and then takes the remaining stars as positional standards. Typically, it finds over a hundred standards in several seconds.
Using DASHA, we obtained BVI photometry of the globular cluster NGC 5927. Unique observational data was kindly provided by Dr. G. Alcaino (Isaac Newton Institute, Chile), and consisted of 17 CCD frames in the B filter, 17 in I, and 13 in V (telescope: ESO's 2.2m at La Silla). The most interesting diagram, B vs. B-I, is included here (Figure 1a); Figure 1b is a histogram of the distribution of B magnitudes. The final color table contains over 5000 stars, of which over 2000 are measured in all three filters. The whole process, starting with AllStar's results, and ending with color-magnitude diagrams, took little over an hour.
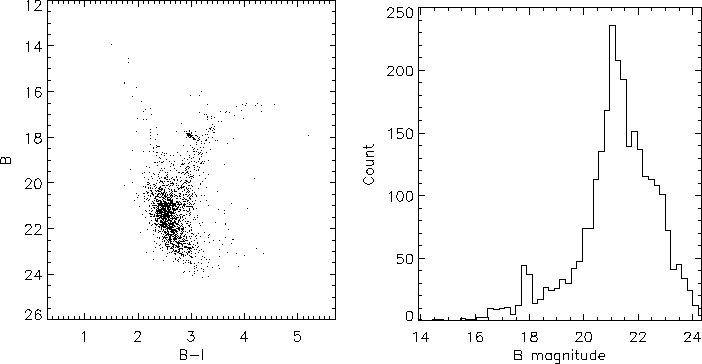
Figure: (a) Color-magnitude diagram, (b) B magnitude
distribution for NGC 5927.
Original PostScript figure (38 kB)
BVRI photometry of three other globular clusters, NGC362, NGC5286, and NGC7099, is in progress at the time of writing.
We welcome any questions and comments about DASHA. Please contact Oleg Smirnov by e-mail at oms@inasan.rssi.ru. DASHA and the PCIPS image processing system are commercial products. Please contact Oleg Smirnov for details.