To make distributed development successful, we have defined interfaces that allow separated groups to work independently of their counterparts at other locations as much as possible. We have defined a common architecture and infrastructure, so that work done at one location is not unnecessarily duplicated at another, and that similar tasks are done in a similar way throughout the project. A single, integrated Archive attends to the needs of all subsystems for persistent storage, and hides details of the underlying database technology. The separation of functional from technical concerns is built into the system architecture through the use of the Container-Component model: application developers can concentrate on implementing functionality in runtime-deployable components, which in turn depend on Containers to provide them with services such as access to remote resources, transparent serialization of value objects to XML, logging, error-handling and security. The resulting middleware, which forms part of the ALMA Common Software (ACS), is based on CORBA and XML.
At the same time, the software is required to make millimeter interferometry accessible even to the uninitiated (while preserving the expert's ability to exercise full control). As ALMA's Science Software Requirements state:
``The ALMA software shall offer an easy to use interface to any user and should not assume detailed knowledge of millimeter astronomy and of the ALMA hardware.
``The general user shall be offered fully supported, standard observing modes to achieve the project goals, expressed in terms of science parameters rather than technical quantities...''
Of course, when complexity is swept under the rug for the sake of the neophyte user, the resulting lump remains. What is made simple for the user will therefore be complex for the software developer. One goal of the system architecture should be to relieve the developer of unnecessary complexity. Our primary vehicle for achieving this is the separation of functional from technical concerns, which is discussed below.
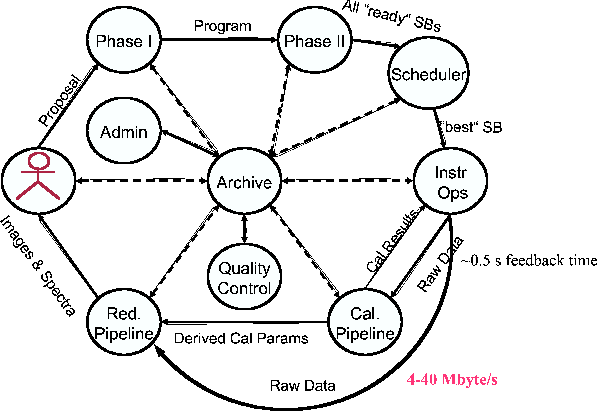
Amidst this storm of incoming data, the online calibration software must be able to
calculate pointing & focus corrections, phase corrections & average phase noise and
feed these results back to the observing process in
![]() ¥ 0.5 s, so that antenna pointing & focus can be adjusted in near-real-time and the time
spent observing target and phase calibrator can be adjusted to match rapidly changing
atmospheric conditions (Lucas 2004).
¥ 0.5 s, so that antenna pointing & focus can be adjusted in near-real-time and the time
spent observing target and phase calibrator can be adjusted to match rapidly changing
atmospheric conditions (Lucas 2004).
Once observations belonging to a given Observing Program are complete, the science data processing, i.e., the production of images via calibration, Fourier transformation and deconvolution, must keep pace (on average) with the rate of data acquisition.
Another important number to keep in mind is the dozen or so institutes on two continents that take part in the development of software for ALMA. The fact that this first number exceeds unity by an order of magnitude conditions many of the architectural and process-related choices we have made, as we will discuss below.
| Challenge | Response | ||
| Changing observing conditions | Dynamic Scheduler | ||
| High data rates | Integrated scalable Archive | ||
| Diverse user community (novice to expert) | Flexible observing tool, GUIs | ||
| Distributed hardware & personnel | |||
| AOS: antennas at 0.5-14 km from correlator | High-speed networks | ||
| AOS-OSF: operators are 50 km from array | Distributed architecture | ||
| OSF-SCO-ARCs: PIs, staff, separated from | CORBA & CORBA services | ||
| OSF by 1000Õs of km, often by many | Container/Component model | ||
| hours in time zone | XML serialization |
The functional architecture further divides these interferometry-related tasks into subsystems that can be developed in relative independence from each other. The technical architecture furnishes these subsystem developers with simple and standard ways to 1) access remote resources; 2) store and retrieve data; 3) manage security needs; and 4) communicate asynchronously with other subsystems and components. In the end, separation of concerns is no more than a variant of the divide-and-conquer strategy that Caesar used to conquer Gaul 2000 years ago.
| Challenge | Response |
| Evolving requirements | Iterative development |
| Changing data rates | Modular, flexible design |
| New observing modes | Scriptable observing procedures |
| New hardware (ACA) | Generic, parameterized design |
| IT advances | Isolation of system-dependent S/W |
| Distributed development | Unified architecture (HLA) |
| Different s/w cultures | Functional subdivisions aligned |
| to existing project organization | |
| Common Software (ACS) | |
| Don't do it twice (but if you | |
| really must do the same thing, do it | |
| the same way everywhere) | |
| E-Collaboration tools | |
| Challenge | Response |
| Evolving requirements | Iterative development |
| Changing data rates | Modular, flexible design |
| New observing modes | Scriptable observing procedures |
| New hardware (ACA) | Generic, parameterized design |
| IT advances | Isolation of system-dependent S/W |
| Distributed development | Unified architecture (HLA) |
| Different s/w cultures | Functional subdivisions aligned to existing |
| project organization | |
| Common Software (ACS) | |
| Don't do it twice (but if you really must do the | |
| same thing, do it the same way everywhere) | |
| E-Collaboration tools |
The principle construct that makes dynamic scheduling possible, is the Scheduling Block [SB], a software object defined to be an indivisible unit of observing activity. Once execution of an SB has started, it can be aborted but not restarted in the middle. An SB will be self-contained to the extent that it will contain all project-specific observations necessary to allow calibration of the data that it produces (typically phase and possibly bandpass calibration; more general calibrations, such as baseline determination and determination of the pointing model, are the responsibility of the ALMA Observatory and lie outside the province of a PI's SBs). The dynamic scheduler will be able to query each SB to answer questions such as 1) What array hardware ( e.g., antenna configuration, receiver bands) do you require? 2) What atmospheric conditions do you need?
The nominal execution time for an SB will be about 30 minutes; PIs can specify longer SBs, but the dynamic scheduler will tend to prefer the shorter ones, all other factors being equal, since these enhance its ability to react to changes in observing conditions. As many, if not most observations of interesting targets will require longer integration times than a single SB allows, multi-SB observations will be the rule, rather than the exception. Quite often, these SBs will not be executed consecutively, but this only presents problems for rapidly varying (pointlike or solar-system sources), for which use of longer SBs will be unavoidable. When an SB has finished execution, either because it has achieved its performance goals or because it has reached its time limit, the scheduler will repeat its selection process.
A Data Access Layer interface to these types of data has been defined, allowing the underlying database technology to be hidden from subsystem developers. The existence of this interface will give the Archive developers the ability to replace this technology when and if it becomes necessary or desirable to do so.
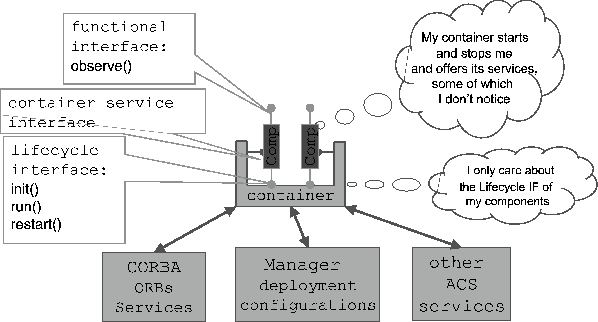
The Container's job is to handle technical concerns centrally and hide them from application developers. It provides convenient access to other components and resources, selected CORBA/ACS Services (Error, Logging, configuration, ...) and enables decisions about deployment (which component(s) should run on which hardware) and start-up order to be deferred until run-time. Should we see a need for additional technical services in the future, these can be integrated into the Container, minimizing any modifications that must be made to the application (Component) software.
Figure 2 illustrates the relationships between Components and their Containers, and between Components and other Components with which they communicate.
An important contribution to the capabilities of the Container/Component framework comes from the multifaceted use of the eXtensible Markup Language or XML (Sommer 2004). We define the structure and content of ``Value Objects'', complex data objects such as Observing Projects, Scheduling Blocks and VOTable headers via XML schemas. Binding classes that allow type-safe native language access to these data structures and that can validate compliance with these schemas are generated automatically by an open-source framework. The Containers provide transparent serialization of these Value Objects to XML, enabling subsystems to exchange and modify them in a language-independent way. Moreover, the Archive has been designed to accept such schema-conformant XML documents directly.
We are currently investigating the utility of generating the XML schemas themselves from an overall observatory data model expressed in the Unified Modelling Language (UML). This approach holds out the promise of more efficient maintenance of the data model itself, drastically shortening the time needed to incorporate the (inevitable) changes to the model that the evolution of ALMA and of our own understanding will make necessary.
Meanwhile, AIPS++ itself is evolving to use a standard, open-source scripting language (Python) to replace its existing, bespoke scripting language (glish). A proof of concept effort is underway to recast AIPS++ tools as Components (in the sense discussed previously), using the C++ and Python Containers provided by ACS. The first phase of this three-phase project has completed successfully, giving us reason to hope that AIPS++ will integrate seamlessly into the ALMA software environment.
ACS has been carefully designed to be independent of commercial software, for example through the use of high-quality open-source ORBs such as TAO and JacORB. It is constantly evolving to meet developers' needs, having reached, as of this writing, Release 3.0. The most recent developments have included the implementation of the Python Container, needed by the subsystem responsible for pipeline data processing, and an all-Java version (albeit with reduced functionality), which is necessary for the developers of the Observing Tool to provide software that can be installed on almost any astronomer's desk- or laptop computer.
At the start of the ALMA software effort there was considerable resistance by developers to the discipline and standardization that is a consequence of ACS. It is testimony to the soundness of the concept of common software, the quality of its implementation and the dedication of the ACS team that developers are now asking that ACS offer more features and support for their activities.
To date, the ALMA Software System has completed an Internal Design Review, a Preliminary Design Review with reviewers external to the computing group, the first ``Critical'' Design Review, and two code releases. The first of these code releases, R0, tested the build procedures and tools and a minimal amount of code, while the second release, R1, successfully implemented a skeletal end-to-end data flow, testing interfaces, communications mechanisms, and developers' understanding of them. The R1.1 release will concentrate on eliminating the problems and mismatches uncovered in R1, while R2 will aim at providing a useable system for the Antenna Test Facility at the site of NRAO's Very Large Array (VLA) in New Mexico. Later releases will build towards support of Early Science Operations in 2007 and, with the benefit of experience in the use of earlier versions of the software, of Full Science Operations in 2012.
It remains to learn from the sad fate of projects whose end product evokes the following from their customers: ``It's beautiful software but not what we wanted.'' We believe that the key to avoiding such a regrettable epitaph is to ensure that user participation doesn't end with the publishing of a requirements document. To this end, a scientist expert in the problem area is assigned to every subsystem development team with the task of 1) providing advice and help to solve problems during development; 2) making sure that requirements are met and that the requirements themselves are up to date; 3) evaluating subsystem progress and redefining requirement priorities when appropriate; 4) ensuring that subsystems interface properly; and 5) helping to develop a test plan and to perform periodic testing and evaluation of the software from a scientific user's perspective.
The user tests represent the culmination of a comprehensive testing strategy. At the lowest, or most detailed level, subsystem developers are responsible for unit tests that verify the correctness of pieces (typically, classes or small groups of collaborating classes) of code. Tools such as JUnit, pyUnit and cppUnit are commonly employed to automate and standardize these tests. A ``test first'' attitude is encouraged. Subsequent automatic performance tests will be used to ensure that timing constraints are met and that data throughput is adequate. The stand-alone subsystem user tests referred to earlier will be performed before subsystem releases with adequate time to allow subsystem developers to respond. Finally, integrated user tests that exercise the complete system will be executed as soon as possible after integrated subsystem releases.
Under the guidance of a management team anchored on both sides of the Atlantic, these collaborations among HLA, ACS, ITS and SE will play an important part in ensuring that the distributed development of the ALMA software, by bringing the scientific and software expertise of many diverse participants to bear on the challenges facing it, can outweigh the added communications effort needed and ultimately prove a major factor in the project's success.
Bridger A. et al. 2004, this volume, 85
Davis, L. et al. 2004, this volume, 89
Farris, A. & Roberts, S. 2004, this volume, [P1-28]
Jeram, B. et al. 2004, this volume, 748
Lucas, R. et al. 2004, this volume, 101
Meuss, H. et al. 2004, this volume, 97
Sommer, H. et al. 2004, this volume, 81
Völter, M. et al. 2003, Server Component Patterns, (New York: Wiley)
Wicenec, A. et al. 2004, this volume, 93