 |
The SkyServer3 has been public since June 2001. This is coded in ASP on a Microsoft.Net server and backed by a SQL Server database. The current database, Data Release 1 (DR1), is over 1TB (with indexes) and subsequent releases will bring this to at least 6TB of catalog data in SQL Server. In fact there will be up to 50 TB of pixel and catalog data and more of this may be put in the database e.g. the points of all SDSS4 spectra have recently been loaded in a separate database. Hence the database could become much larger than 6TB. The SkyServer site allows interactive queries in SQL5. The results of some of these queries are large; we have seen as many as 12 million rows downloaded in an hour the site is averaging 2M hits per month. Considering this is running on a $10k server the site performs extremely well. However in certain circumstances we have experienced problems. Complex queries can swamp the system and erroneous queries may run for a long time but never complete.
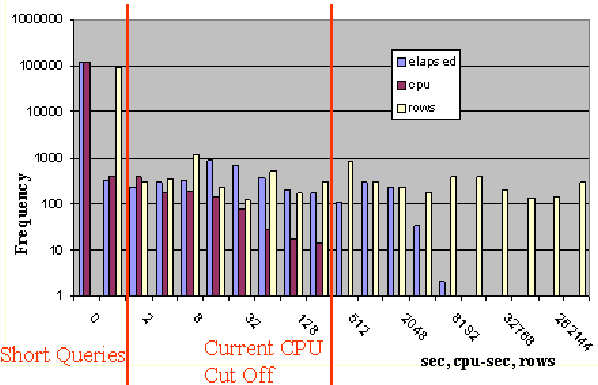
Generally, the execution time of result set sizes follow a natural power law, see figure 1. Hence there is not particularly obvious point at which queries could be cut off. All queries currently run at the same priority- there is no ranking or "nice" system built into SQL Server (or any other DB products). While this may not be a problem in itself, long queries can slow down the system, causing what should be quick queries to take much longer. Some long queries are returning data to a user over an Internet connection; frequently time is spent transferring the data, not extracting it, but a database resource is still tied up. We have seen as many as twelve million rows (20GB) downloaded in one hour. These large transfers are unnecessary; this data is often used only to make comparisons against a small local set.
|
We have developed a system6to address these problems, particularly to partition queries and allow rudimentary load balancing across multiple machines, guarantee query completion/abortion, provide local storage for users, and separate data extraction/download from querying. This will be pertinent for the virtual observatory as the SkyNode protocol begins to mature (Yasuda et al. 2004, Budavári et al. 2004)
We have set up multiple queues based on query length. Jobs in the shortest queue are executed instantly, while jobs in all other queues are executed sequentially (limited simultaneous execution is allowed). Query execution time is strictly limited by the time assigned to a particular queue, and queues are executed on separate machines mirroring the same data. Hence there will no longer be ghost jobs hanging around for days, nor can a long query hinder execution of a shorter one; a job may take only as long as the limit of its queue, and different types of jobs are executed on different machines.
There is a query estimator in SQL server however its accuracy is questionable and for our first beta of this system we have decided not to actively determine query execution time. This responsibility is left to the user; they decide how long they think their query will take and choose the appropriate queue accordingly. As mentioned previously queries exceeding queue time limit will be canceled. We do provide autocomplete functionality that will move the query to the next queue if it times out in its original queue. In a future release we may use the statistics gathered on jobs to develop a heuristic for estimating query lengths and automatically assigning them to queues.
Queries submitted to the longer queues must write results to local storage, known as MYDB, using the standard into syntax e.g.
select top 10 * into MYDB.rgal from galaxy where r < 22 and r >21The MYDB idea is similar to the AstroGrid MySpace (Walton et al. 2004) notion. We create a SQL Server database for the user dynamically the first time MYDB is used in a query. Upon creation, appropriate database links and grants are made such that the database will work in queries on any database. Since this is a normal database the user may perform joins and queries on tables in MYDB as with tables in any other database. The user is responsible for this space and may drop tables from it to keep it clear. We have initially assigned each user 100MB but this is configurable on a system and per user basis.
Some users may wish to share data in their MYDBs. Any user with appropriate privileges may create a group and invite other users to the group. Any invited user will have to accept to be part of the group. A user may then publish any of his MYDB tables to the groups of which he is a member. Other group members may access these tables by using a pseudo database name consisting of the word group followed by the id of the other user followed by the table name e.g. if the adass user published the table rgal and you were in a group with adass you may access this table using GROUP.adass.rgal.
Tables from MYDB may be requested in FITS, CSV, or VOTable7 format. Extraction requests are queued as a different job type and have their own processor running. The file extraction is done on the server and a URL to the file location is put in the job record upon completion. On the Web site group tables also appear in the extraction list. Currently a user may also upload a CSV file of data to an existing table in MYDB. Having the table created before upload avoids problems of intended types. We hope the ability to upload data and the group system will reduce some of the huge downloads from our server.
Apart from the short jobs, everything in this system is asynchronous and requires job tracking. This is simply done by creating and updating a row in a Jobs table in the administrative database. However this also requires users to be identified and associated with the jobs. Identification is also required for resolution of MYDB. A user may list all previous jobs and get the details of status, time submitted, started, finished etc. The user may also resubmit a job.
Budavári, T., et al. 2004, this volume, 177
Walton, A., et al. 2004, this volume, 601
Yasuda, N., et al. 2004, this volume, 293