 |
As has been charted by Top500.org for the past decade, peak computer performance continues to grow at an impressive clip. However, these advances in parallel and distributed computing tend to be accessible to only a small portion of researchers, mainly those within focused research projects at national, university, and corporate laboratories. These groups characteristically benefit from generous funding and can afford to purchase (or build) the best equipment and hire whatever staff is necessary to program and maintain it.
At the other end of the performance spectrum are individual researchers and small collaborative groups. These are by far the more common organizational units in which science is daily practiced, and cumulatively represent a much larger fraction of the total researcher population. Yet the scale of computing power available to many of these researchers, or perhaps more accurately that which is actually used by them on a regular basis, remains merely the desktop workstation.
A variety of issues inhibit the adoption of high performance computing (HPC) by the individual, many of which can be grouped under the rubric of the buy-in problem. After several decades of research it is generally accepted that parallel and distributed programming has not kept pace with improvements in hardware (Hwang & Xu 1998). Despite the breadth of programming models available, HPC has not evolved into the mainstream, and skilled programmers are still hard to find. The complexity of industrial-strength HPC toolkits typically requires a significant investment of time and learning, not only for application or algorithm development, but also for installation and maintenance, especially on today's heterogeneous networks. Our experience is that few practicing scientists have the time or inclination to cultivate these skills (nor, as can be the case, do their technical support staff), with the net effect being that much of the computing potential available to them, at least in principle, goes unused.
This trend manifests itself at several levels. The clearest indication is at the granularity of the network, where the desire to harness the CPU cycles of idle machines has motivated an entire subdiscipline of computer science. The second indication stems from the cycles of hardware upgrades which play out at every computing center. In step with Moore's Law, our older machines are replaced with newer ones, with few second thoughts as to their ultimate destination; as often as not these otherwise functional systems wind up collecting dust in a dark closet. Lastly, observe that while we are at the cusp of another evolutionary step in desktop computing, namely the emergence of the personal multiprocessor system, the extra CPUs in such machines are as yet rarely employed in general scientific development, particularly within the analysis packages used most frequently by astronomers. The wasted CPU cycles in each of these cases would in principle be straightforward to reclaim if parallel and distributed computing skills were more commonplace.
Together these factors create a formidable entry barrier for HPC newcomers, a class into which--drawing from our collaborations at several international research centers--a majority of astronomers still fall, and strongly motivate our investigation of tuplespaces (TS) for rapid distributed computing development.
Linda tuplespaces have been offered as custom C, C++, and Fortran compilers, with a commercial license that can be a barrier to adoption for smaller research groups. Furthermore, as is the case with other parallelizing compilers, and with message passing libraries, such Linda programs are architecture-specific binary code, meaning one cannot compile a single Linda application for use on highly heterogeneous networks.
The marriage of the TS model with the popular Java platform addresses these concerns, and extends Linda with transactions, tuple leasing, and event notification. The arrival of two free, commercial-grade Java tuplespace (JTS) platforms--Sun's JavaSpaces (Freeman et al. 1999) and IBM's TSpaces (Wyckoff et al. 1998)--opens an entirely new avenue of exploration in distributed computing with commodity technology.
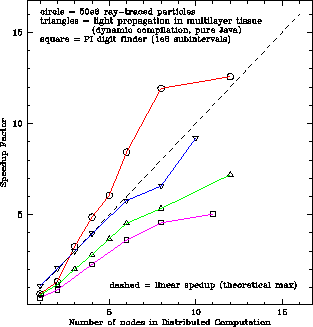
It is our contention that, if asked to choose between achieving theoretically maximum performance some unspecified N months into the future or achieving suboptimal but good performance in a fraction of that time, many researchers would gladly select the latter. In Noble & Zlateva (2001) we discuss JTS in this context and present benchmark results which exhibit good speedups for several parametric master/worker algorithms, relative to both sequential Java and native compiled C (Figure 1).
Other researchers have also reported substantial speedups using JTS (Batheja & Parashar 2001, Teo et al. 2002). While several weaknesses of JTS were noted in our work (notably communication latency and a lack of collective broadcast/gather/reduce communication operations), they nonetheless remain enticing as a poor man's HPC platform by addressing off-the-shelf numerous issues with distributed systems.
First, by remaining wholly ignorant of the details of the computations they perform, generic JTS workers may be written just once for a variety of computations, and breezily deployed on any Java-capable platform. While it is true that similar levels of runtime generality and portability are attainable by other means, e.g., Java RMI, most fall short of the ease of use and semantic clarity that is built in to JTS in that the programmer can be required e.g., to abstract the network interactions themselves (or use a package which does so), use RPC compilers to explicitly generate client stubs, and so forth.
Second, such workers need be started only once per compute node, after which they idle as low-consumption daemons until tasks appear in the space. With native-compiled PVM, MPI, or OpenMP implementations, however, master and worker tend to be far more tightly coupled. This approach is typically characterized by workers being coded with explicit algorithmic knowledge and masters being directly responsible for the spawning of workers. Together these make the typical worker unsuitable for use in a wide variety of computations, and present additional difficulties on heterogeneous networks as one body of compiled code cannot be used on multiple architectures.
It is worthwhile to note that using N=1 worker is effectively a sequential
invocation, while parallelism is achieved by using N=k![]() 1 workers.
This semantic clarity can be very beneficial to the application developer,
since one of the more difficult aspects of programming for concurrency
is that sequential algorithms frequently do not map cleanly to parallel
implementations. In such cases it is difficult or impossible to utilize
one body of sourcecode for both sequential and parallel execution.
1 workers.
This semantic clarity can be very beneficial to the application developer,
since one of the more difficult aspects of programming for concurrency
is that sequential algorithms frequently do not map cleanly to parallel
implementations. In such cases it is difficult or impossible to utilize
one body of sourcecode for both sequential and parallel execution.
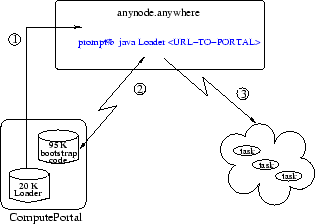
Recent work, though, shows that combining network class loaders with JTS can eliminate many of these difficulties (Noble 2000, Lehman et al. 2001, Hawick & James 2001). In fact, in the 47-node MAN testbed used to derive the results of Figure 1: the JTS system software was installed on non-privileged diskspace, and was booted from an ordinary user account, master and workers were run from ordinary user accounts, and 6 of the 14 machines used did not even have a local JTS installation.
Users electing to participate in the distributed computation framework need only install a network launcher onto the prospective node(s), the cost of which can be as small as a 20K download.2 At runtime the loader is pointed at the established portal to retrieve the bootstrap jar and invoke the worker class within, after which the worker contacts the space and idles for compute tasks. Whatever class loader is used, it need be downloaded just once per node, after which it can be reused regardless of how many revisions are made to the bootstrap code or computation framework.
With this approach it is no longer necessary to consume administrator time to configure or employ distributed systems--a JTS solution may be installed and activated without knowledge of the system password on any machine; nor is it necessary to maintain multiple native binary builds--of either the HPC toolkit or your computational codes--to utilize multiple CPU architectures in a single distributed computation. The significance of this technique increases in direct proportion to both the number and architectural diversity of nodes within the computation environment, as well as the workload of your system administrators.
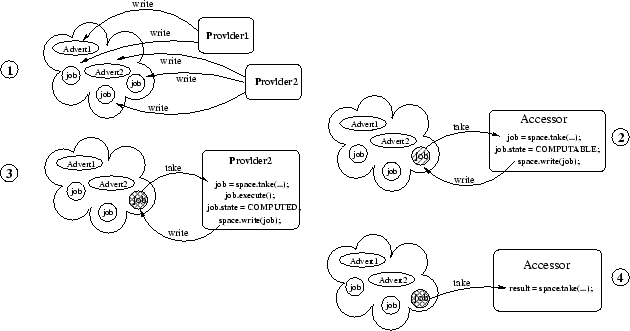
Likewise, the separation of advertisement from job execution yields an implicit mechanism for detecting a saturated provider without further contributing to that saturation: if an advertisement exists in the portal with no corresponding job tuples then the provider must be busy servicing other requests. A client can detect this state without issuing an ill-fated request (yet more work for the overloaded provider) doomed to merely timeout. This fosters smoother client operation, especially important when human interaction is involved, and promotes deterministic behavior of the system as a whole. The use of jobs as quanta of work lets providers retain full control over how much community service they will perform, and when, and makes it virtually impossible for them to saturate from requests. While the space itself is a potential saturation point, the tasks it handles (mostly funneling small-ish tuples back and forth) are not computationally expensive, and its function can be replicated for scalability as needs arise (although more investigation is needed in this area).
Another form of load balancing is manifest in the ability of the space to store partial results. Imagine for instance a provider who offers a computationally expensive service that takes N input parameters. Since the result of that computation can be stored in the space (or a reference to it if the result, e.g., a file, is too large), new requests with matching inputs need not result in entirely new service invocations at the provider.
Finally, note that while service discovery and requests are coordinated by the space, its use is not mandatory. A provider is free to negotiate more effective means of interaction with the requestor, and in fact archive retrievals in our testbed are carried out by direct download between the hosting site and client.
For one, many of the features described here--simple service coordination, accumulation and persistence of partial results, asynchrony, transactional support, fault tolerance, and dynamic lifetime management--are not well-supported in other service hosting implementations, such as those providing Web Services through a UDDI registry. These factors--plus the heavy bias of UDDI towards commerce, and the performance of SOAP (Davis & Parashar 2002, Govindaraju et al. 2000)--should concern those considering adopting Web Services for scientific use. In response the grid community is developing more robust alternatives, such as the Open Grid Services Architecture (forming the core of the next generation Globus 3.0 Toolkit, which incidentally also requires Java for service management, though wider language support is planned) and the Web Services Discovery Architecture (WSDA). Until these mature, however, the scientific community is left with few off-the-shelf options for service management. Our JTS-based scheme productively fills this interim niche.
Next, a commitment to use Java somewhere within a project does not mandate its use everywhere, given the availability of the Java native interface (JNI) and fork()/exec(). Our testbed amply demonstrates this by seamlessly binding libraries, applications, and HTTP services--legacy and new--written in a variety of compiled and interpreted languages. In principle ``using Java to talk to the network'' is not dissimilar from ``using XML to talk to the network'': either would represent just another layer within a codebase, each with its own advantages and disadvantages.
Finally, note that our aim in comparing JTS with Web Services is didactic, rather than to suggest that our approach to service management should, or even can, supplant the use of Web Services in the VO arena. Our hope is that the more intriguing features of our portal find their way into evolving registry schemes, and that we can find a way to embrace emerging grid and VO standards while not sacrificing the clear gains JTS have delivered in our work. We anticipate that the latter will not be difficult, since the Java platform is by a large margin the dominant vehicle for Web Services deployment (SoapWare.org,3InfoWorld survey).
While in its present form the testbed should adequately fulfill its purpose as a local proving ground for VO datamodel development, plenty of room for improvement remains, notably in the areas of replication and scalability, interoperability with web-services, adoption of emerging VO standards, streamlining agent interactions with event notification and broader use of JNI, and more graceful co-existence with firewalls.
Batheja, J. & Parashar, M. 2001, Proc. IEEE Cluster Computing, 323
Carriero, N. & Gelernter, D. 1988, ACM SIGPLAN Notices, 23(9), 173
Cresitello-Dittmar, M. et al. 2003, this volume, 65
Davis, D. & Parashar, M. 2002, IEEE Clust. Comp. and the GRID
Freeman, E., Hupfer, S. & Arnold, K. 1999, JavaSpaces: Principles Patterns, and Practice (Reading, MA: Addison-Wesley)
Gelernter, D. 1985, ACM Trans. on Prog. Lang. and Sys. 7(1), 80
Gelernter, D. & Carriero, N. 1992, Comm. of the ACM 35(2), 97
Hawick, K. & James, H. 2001, Proc. IEEE Cluster Computing, 145
Hwang, K. & Xu, Z. 1998, Scalable Parallel Computing (Boston: McGraw-Hill)
Lehman, T. et al. 2001, Computer Networks, 35, 457
Noble, M. & Zlateva, S. 2001, Lecture Notes in Computer Science (Berlin: Springer-Verlag), 2110, 657
Teo, Y. M., Ng, Y. K., & Onggo, B. S. S. 2002, Proc. 16th IEEE Work. on Parallel and Distrib. Simulation, 3
Wyckoff, P. et al. 1998, IBM Systems Journal, 37(3), 454