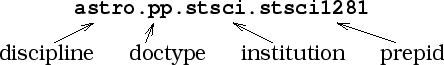
Against this background, the astronomical preprint has made a much less successful transition to electronic distribution. Preprints are the historical channel for rapid communication of results in astronomy. Preprints have traditionally been produced in an institutional framework to demonstrate an organization's quality and vitality. But isolated institutional preprint web sites make it difficult for a user to discover new and interesting preprints. The centralized Los Alamos National Laboratory astrophysics preprint archive is one solution of the discovery problem. But this service remains to be integrated into the on-line astronomical literature identified with Urania.
We are developing a distributed system for integrating preprint collections maintained at participating institutions. Institutional participation provides the best assurance of correctness and currency, distributes the workload and resource requirements, and satisfies an institution's desire to display its own achievements. The system will allow users to locate documents anywhere in the collection by means of a single query, or to search through the holdings at a single institution. The system integrates preprints into the on-line literature by tracking a preprint through to final publication: a hyperlink to a preprint will resolve to the on-line final paper, once it is published. The system could eventually be integrated with journal production by providing manuscripts for referees and production staff. In return, journals could automatically supply the final URL of each preprint. At the moment, however, we are working on a system to facilitate and preserve the preprint tracking being done by hand by librarians.
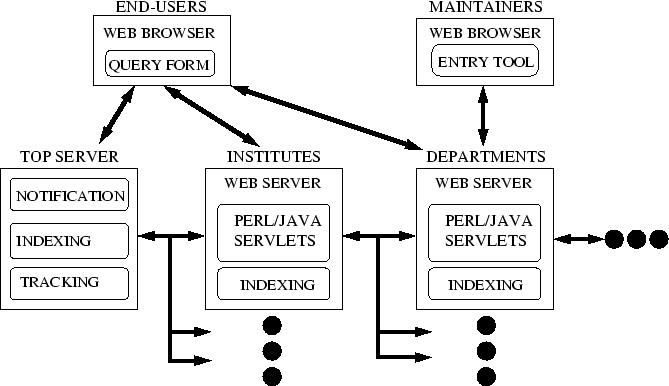
Our prototype preprint service is a hierarchical system. A central authority tracks participating institutions. Each institution can maintain a number of document collections, and may also grant authority over parts of its ``preprint namespace'' to subordinate or ``child'' servers, at the departmental level, say, and so on. Each node in the prototype system has identical software, although ``lite'' sites are also envisioned.
The practical key to the Urania system was a standard naming scheme, known as ``bibcodes,'' for journal articles. Our preprint identifiers, or ``prepcodes,'' reflect the hierarchical nature of the system, and are modeled on the HANDLE system, used by the NCSTRL project, for example. Preprint identifiers consist of four components:
The first field allows for collections in other disciplines. Doctypes might include other ``gray literature'' categories, like technical reports and observatory manuals. The institution code is assigned by the central authority, to avoid duplication, while the prepid field is largely arbitrary.
Metadata for each document are keyed by preprint identifier. Metadata include a title, authors and affiliations, an abstract, pointers to author contributed TEX and PostScript files, if present, and the location of the final published paper. The metadata are indexed for searching, and used to dynamically generate most web pages. Metadata are in a format that is nearly XML. Other metadata files describe each collection, and encapsulate parent-child relationships.
At each node of the system, a name resolver provides access to the metadata associated with each prepcode in its assigned name space. Prepcodes at child nodes are passed down the hierarchy to child servers, and unrecognized prepcodes are passed up the hierarchy to the parent server. The central server forwards valid prepcodes to the appropriate institutional server, and catches invalid prepcodes.
A parent server can collect metadata from its children, allowing it to create an index spanning all collections in its name space, and allowing the central authority to index all collections. A user viewing an institutional site and wishing to search a larger collection of documents is directed to the search page at the parent site. This mechanism could be the basis of a notification service, which would take note of new items.
The overall architecture is sketched in Fig. 1. The ``Top Server'' will have many child ``Institute Servers,'' each of which can also be a parent of servers at a lower (departmental, for example) level. That is, the diagram can be expanded both horizontally and vertically, as indicated by dots. Arrows indicate the exchange of metadata and name resolver requests between parent and child, and the user's ability to query the central server or local servers. Site management tools are shown in the upper right of the figure.
Fernique, P., Ochsenbein, F., & Wenger, M. 1998, in ASP Conf. Ser., Vol. 145, Astronomical Data Analysis Software and Systems VII, ed. R. Albrecht, R. N. Hook, & H. A. Bushouse (San Francisco: ASP), 466
Hanisch, R. J., Payne, H. E., & Hayes, J. J. E. 1994, in ASP Conf. Ser., Vol. 61, Astronomical Data Analysis Software and Systems III, ed. D. R. Crabtree, R. J. Hanisch, & J. Barnes (San Francisco: ASP), 41