Next: Modelling Spectro-photometric Characteristics of Nonradially Pulsating Stars
Up: Computational Astrophysics
Previous: VRML and Collaborative Environments: New Tools for Networked Visualization
Table of Contents -- Index -- PS reprint -- PDF reprint
U. Becciani, V. Antonuccio-Delogu, M. Gambera and A. Pagliaro
Osservatorio Astrofisico di Catania, Città Universitaria, Viale A. Doria, 6 - I-95125 Catania - Italy
R. Ansaloni
Silicon Graphics S.p.A. St.6 Pal. N.3, Milanofiori
I-20089 Rozzano (MI) - Italy
G. Erbacci
Cineca, Via Magnanelli, 6/3 I-40033 Casalecchio di Reno (BO) - Italy
N-body simulations are one of the most important tools in contemporary theoretical cosmology, however the number of particles required to reach a significant mass resolution is more larger than those allowed even by present-day state-of-the-art massively parallel (Gouhing 1995; Romeel 1997 & Salmon 1997) supercomputers (hereafter MPP). The most popular algorithms are generally based on grid methods like the P3M. The main problem with this method lies in the fact that the grid has typically a fixed mesh size, while the cosmological problem is inherently highly irregular. On the other hand the Barnes & Hut (1986, hereafter BH) oct-tree recursive method is inherently adaptive, and allows one to achieve a higher mass resolution. Because of these features, the computational problem can easily become unbalanced and cause performance degradation. For this reason, we have undertaken a study of the optimal work- and data-sharing distribution for our parallel treecode.
Our Work- and Data-Sharing Parallel Tree-code (hereafter WDSH-PTc)
is based on this algorithm tree scheme, which we have modified to run on a
shared-memory MPPs (Becciani, 1996).
The BH-Tree algorithm is a NlogN procedure to compute
the gravitational force,
a more detailed discussion on the BH tree method can be found in
Barnes & Hut (1986). For our purposes, we can distinguish three main phases in
each timestep: TREE_FORMATION (TF), FORCE_COMPUTE (FC),
UPDATE_POSITION. Besides, in the FC phase we can distinguish
two important subphase: TREE_INSPECTION (TI)
and ACCEL_COMPONENTS (AC).
During the FC phase each PE computes the acceleration components for each body in asynchronous mode and only at the end of the phase an explicit barrier statement is set. Our results show that the most time-consuming phases (TF, TI and AC) are executed in a parallel regime. Tests were carried out, fixing the constraint that each PE executes the FC phase only for all bodies residing in the local memory. A bodies data distribution ranging from contiguous blocks (coarse grain: CDIR$ SHARED POS(:BLOCK,:)) to a fine grain distribution (tf) (CDIR$ SHARED POS(:BLOCK(1),:)) was adopted. We studied different tree data distributions ranging from assigning to contiguous blocks (tc) a number of cells equal to the expected number of internal cells (NTcell), [Salmon 1990](coarse grain: CDIR$ SHARED POS_CELL(BLOCK(:NTCELL/N$PES),:)), to a simple fine grain distribution (CDIR$ SHARED POS_CELL:BLOCK(1),:)), (tf).
All the tests were performed for two different set of initial conditions,
namely uniform and clustered distribution
having 220 particles each and they were carried out using from 16 to
128 PEs. In
Tab. 1 we report only the most significant results obtained
with 128 PEs.
| PE# | p/sec | FC phase | T-step | UF | |
| 1Mun_tf_bf | 128 | 4129 | 230.05 | 249.5 | 4.22 |
| 1Mcl_tf_bf | 128 | 3832 | 250.32 | 268.81 | 4.57 |
| 1Mun_tf_bm | 128 | 3547 | 270.51 | 290.45 | 5.90 |
| 1Mcl_tf_bm | 128 | 3308 | 291.63 | 312.26 | 6.32 |
| 1Mun_tf_bc | 128 | 4875 | 186.31 | 205.32 | 4.14 |
| 1Mcl_tf_bc | 128 | 4490 | 203.37 | 222.72 | 4.38 |
| 1Mun_tc_bc | 128 | 837 | 1051.93 | 1230.0 | 16.33 |
| 1Mcl_tc_bc | 128 | 750 | 1173.24 | 1373.4 | 17.62 |
The fine grain bodies data distribution (bf) is obtained using a block
factor N=1; i.e., bodies are shared among the PE but there is no spatial
relation in the body set residing in the same PE local memory.
The medium grain bodies data distribution (bm) is obtained using a block
factor ![]() ; i.e., each PE
has two data block of bodies properties residing in the local memory,
each block having a close bodies set.
At the end the coarse grain bodies data distribution (bc) is obtained using
a block factor
; i.e., each PE
has two data block of bodies properties residing in the local memory,
each block having a close bodies set.
At the end the coarse grain bodies data distribution (bc) is obtained using
a block factor ![]() ; i.e., each PE has one close data set block
of bodies residing in the local memory.
The results reported in Tab. 1 show that the best bodies data
distribution, having the highest code performance
in terms of particles per second, is obtained using the block factor
; i.e., each PE has one close data set block
of bodies residing in the local memory.
The results reported in Tab. 1 show that the best bodies data
distribution, having the highest code performance
in terms of particles per second, is obtained using the block factor
![]() as expected, due to the data locality effect.
as expected, due to the data locality effect.
Here, we present the results of a new DLB strategy, that allows us to avoid any large overhead. The total time spent in a parallel region Ttot, can be considered as the sum of the following terms
| Ttot=Ts+ K Tp/p + To(p) | (1) |
In the FC phase, there are no serial regions, so ![]() to the length of the interaction list (IL).
Using a coarse grain subdivision, each PE has a block of close bodies in the
local memory (
to the length of the interaction list (IL).
Using a coarse grain subdivision, each PE has a block of close bodies in the
local memory (![]() ); in a uniform distribution initial condition, the PEs having
extreme numeration in the
pool of available PEs, have a lower load at each timestep.
This kind of effect may be enhanced, if a clustered initial condition is used.
If the number of PEs involved in the simulation increases we note that
the data dispersion on the T3D torus increases.
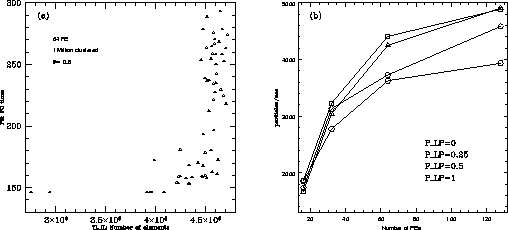
Our results do not show (see Figure 1a)
the existence of a relationship between the time spent in the FC phase
and the total length of the IL.
The adopted technique is to perform a load redistribution
among the PEs so that all PEs have the same load in the FC phase.
We force each PE to execute this phase only for a fixed
portion of the bodies residing in the
local memory NBlp.
NBlp is given by
); in a uniform distribution initial condition, the PEs having
extreme numeration in the
pool of available PEs, have a lower load at each timestep.
This kind of effect may be enhanced, if a clustered initial condition is used.
If the number of PEs involved in the simulation increases we note that
the data dispersion on the T3D torus increases.
Our results do not show (see Figure 1a)
the existence of a relationship between the time spent in the FC phase
and the total length of the IL.
The adopted technique is to perform a load redistribution
among the PEs so that all PEs have the same load in the FC phase.
We force each PE to execute this phase only for a fixed
portion of the bodies residing in the
local memory NBlp.
NBlp is given by
| (2) |
| (3) |
The results obtained lead us that
it is possible to fix a Plp value allowing the best
code performances. In particular, we note
that is convenient to fix the Plp value near to ,
that is maximize the load balance.
The data show that, fixing the PEs number and the particles number, the
same Plp value gives the best performance both in uniform and clustered conditions.
This means that it is
not necessary to recompute the Plp value to have good
performances.
The results obtained using the WDSH-PTc code, at present, give performances comparable to those obtained with different approaches such as Local Essential Tree (LET) (Dubinski 1996), with the advantage of avoiding the LET and an excessive demand for memory. Besides, a strategy for the automatic DLB has been described, which does not introduce a significant overhead.
The results of this work will allow us to obtain, in the next future, a WDSH-PTc version for the CRAY T3E system, using the HPF-CRAFT and the shmem library. The new version will include an enhanced grouping strategy and periodic boundary conditions (Gambera & Becciani 1997).
Gouhing, X., 1995, ApJ. Supp., 97, 884
Romeel, D.,& Dubinski, J., Hernquist, L., 1997, New Astronomy, 2, 277
Salmon, J., 1997, Proc. of the 8th SIAM Conf.
Barnes, J., & Hut, P., 1986, Nature, 324, 446
Becciani, U., Antonuccio-Delogu, V., & Pagliaro, A., 1996, Comp. Phys. Com., 99, 9
Salmon, J., 1990, Ph.D. Thesis, Caltech
Dubinski, J., 1996, New Astronomy, 1, 133
Gambera, M., & Becciani, U., 1997, in preparation
Next: Modelling Spectro-photometric Characteristics of Nonradially Pulsating Stars
Up: Computational Astrophysics
Previous: VRML and Collaborative Environments: New Tools for Networked Visualization
Table of Contents -- Index -- PS reprint -- PDF reprint