 |
For years StarView, a database query and data retrieval tool for the Space Telescope Science Institute, relied on a complex third party LISP-based program (QUICK) to construct valid SQL queries for the one database it could query. This limited our ability to support StarView as we could not easily add new rules to the system without completely rebuilding the query engine. Furthermore, QUICK did not have the ability to create SQL that would join tables in different databases (but hosted on the same server). Finally, the cost of upgrading to a new version of QUICK was prohibitively high.
Our solution was to develop a rather simple database table driven Perl CGI program which is able to take as its input a skeleton SQL program. This may come from a program or other web page. In the query only the SELECT and user qualified WHERE clause are specified; no FROM or WHERE clause join information is included. The service then returns a fully qualified and syntactically correct query for the host database SQL program that can be used to get the information the user needs. Thus, an additional layer of abstraction for dealing with databases is created, freeing the user from having to know how tables are related in the database.
In this paper we discuss the design and algorithm used to make Autojoin work as well as discuss how, when combined with a robust and searchable description of all the fields that can be publicly queried in the database, it allows users to tailor their questions to the database with ease and a high rate of success.
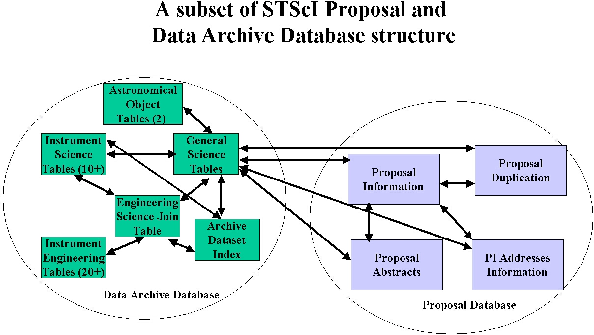
At STScI, information about observed and planned observations is stored in several databases. These databases are rather large, and have many different rules for joining tables in one database, much less between separate databases. Different subsystems often map into the database schema differently, leading to complex intersystem data structures. Figure 1 gives a small example of the complexity of this system for a selection of tables from two of the STScI databases.
As illustrated in Figure 1, there are many different routes to join related information. To create a join from the Proposal Abstract to information in an Instrument Engineering table requires several interim join tables. Users cannot be expected to know this.
Laying out the database structure in this way reveals clear patterns in how the database works. When one looks at the keys that are used to join these tables, further patterns develop. It was clear from this exercise that a simple rule based system for creating arbitrary queries to the database could be constructed. We started by cataloging all the tables to be exposed to users. We then categorized these tables to group tables that join to other tables using the same keys. Finally we constructed rules for joining between different categories of tables. For some tables, interim join tables were required, and noted in the join rules.
With the categorization done, we created three tables to capture this information. The Table Categories table contains the list of all publically available tables and the databases that house them. For some databases at STScI a prefix for each table is designated to allow for a namespace differentiation of shared fields among different tables. For example two tables might have an RA field with prefixes one_ and two_. The field in table one would be called one_ra, while the other is two_ra. This prevents database field namespace conflicts in these complex databases while preserving shared field names for common fields. The last field sorts these tables into categories. Tables in the same category join with other tables the same way.
The Category Joins table lists all the possible joins between two table categories listed in the Table Categories table. Each join is assigned a join number. The rules for how to join these two tables are listed in the Join Methods table, where the join number from the Category Joins table indicated which rule to use for joining those tables. Examples of these tables follow.



The autojoin algorithm takes these three tables and finds a path that uniquely joins each table. It is:
This algorithm allows us to find joins simply and quickly and allows intermediate joins to tables as well. StarView uses this algorithm in a simple Perl CGI script. Its use has both improved the performance of the program and diminished the amount of support needed to update the system.
Kennedy, B. & Mayhew, B. 1999, in ASP Conf. Ser., Vol. 172, Astronomical Data Analysis Software and Systems VIII, ed. David M. Mehringer, Raymond L. Plante, & Douglas A. Roberts (San Francisco: ASP), 383
Williams, J. 1994, in ASP Conf. Ser., Vol. 61, Astronomical Data Analysis Software and Systems III, ed. D. R. Crabtree, R. J. Hanisch, & J. Barnes (San Francisco: ASP), 96