 |
Imagine a system which has unified access to archived data, to telescopes and to bibliographic data. In addition the system has intelligent agents (IAs) which can interpret the results.
In this paper I hope to persuade you that such a system, with a seamless interface between telescopes and databases, indeed making telescopes look like databases and visa versa, will bring enormous benefits.
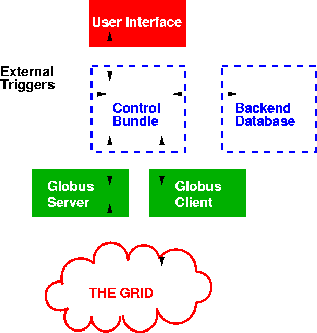
There are two fundamental ideas behind eSTAR which make it a unique project. The first is to treat both telescopes and databases in as similar a fashion as possible, both being made available as a resource on the `Observational Grid'. The second is that the main user of that grid should not be humans making observing requests, but should be intelligent agents.
The design is analogous to computational grids, with no overall supervisor, giving the system scalability with multiple agents talking to multiple nodes.
Intelligent agents submit requests to nodes on the network rather than commands. Each telescope has its own scheduler, which can talk to the agents using the Robotic Telescope Markup Language (RTML) transported over Globus middleware.
A typical sequence begins with the IA carrying out resource discovery, using LDAP to characterise each telescope node and associated instrument suite. Next each telescope is asked by the agent whether it could carry out a particular observation, each node returning a weighted score which encodes the predicted quality of the observation.
The IA will then select the node it wishes to carry out the observation, which will usually be the highest scoring node, and requests that the observation be put in the nodes observing queue by its scheduler.
Once the observation is complete the raw and reduced data are made available to the IA via the grid.
|
 |
One can view the eSTAR network as a unified information grid, within which intelligent agents live.
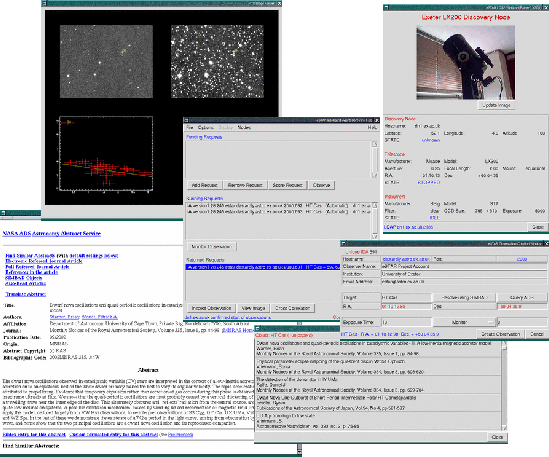
The current prototype agent, see Figure 1, cross correlates the point source catalogue returned by the telescope node with USNO-A2 (in real time) in an attempt to find candidate variable stars, datamining SIMBAD for possible known variables to match the candidate stars.
If the candidate turns out to be a dwarf nova of interest, then the IA will request further followup observations from the network of telescope nodes.
We have been pleasantly surprised by the speed of the cross-correlation stage, which normally completes in 4-10 seconds, including recovering data from three different web sites, indicating that the IA would not be the limiting factor in a system which would be expected to react rapidly to external triggers.
While the prototype agent does lack complexity, it was deliberately developed
in a modular fashion to maximise code reuse, and could be trivially
re-engineered to handle a very different science goal. For instance, to
listen for and response to external triggers such as ![]() -ray burst alerts.
-ray burst alerts.
Indeed, our vision is that agents should be developed by astronomers to address their own science problems, perhaps using some `agent builder toolkit.'
For the prototype we have made use of off the shelf hardware, Meade LX200 and ETX telescopes with SBIG and Apogee CCD cameras, as telescope nodes.
However in general a node is any telescope, or archive, which delivers astronomical data or other resources using a uniform interface. From the point of view of an intelligent agent (or indeed a astronomer) there is little difference between a telescope and a database except the timestamps on the data.
Currently the project makes use of Globus IO to transport RTML documents between the agents and the discovery nodes, with SSL encryption providing a secure data stream.
Additionally, a new version of RTML (Pennypacker et al. 2002) has been developed by the project, with our improvements being rolled back into the ongoing development of the protocol.
We are currently developing the software to make use of emerging web services, and re-engineering the agent to support the next generation Globus Toolkit using Open Grid Service Architecture (OGSA), within which SOAP and WSDL will provide natural language neutral interoperability between the components of the system.
Additionally we are looking to deploy the system on research class telescopes such as the Liverpool Telescope and the United Kingdom Infra-Red Telescope (UKIRT).
We view it as vitally important that federated databases and automated telescopes should share a common interface, as there is little, if any, fundamental differences between them other than the time it takes to return the data and the date stamp.
However if a system similar to this is to become widespread, the idea of requesting observations is equally important. This allows telescopes to join the network and retain their independence, with the intelligent agent contributing, perhaps, only a small fraction of the observations to the telescope scheduler.
Furthermore, telescopes can and must be able to reject requests from an IA if, for example, the astronomer to whom the IA belongs has no time allocated on the telescope.
Pennypacker C. et al. 2002, A&A, in press